随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,百度,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
网络爬虫是一个自动提取网页的程序(网络蜘蛛),它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件.
搜索引擎中网络爬虫的设计分析
1】 网络爬虫高度可配置性。
可以配置网络参数,例如带宽等等
2】 网络爬虫可以解析抓到的网页里的链接
这是必须的,要不你爬什么呢?
3】 网络爬虫有简单的存储配置
爬下来的东西要怎么存
4】 网络爬虫拥有智能的根据网页更新分析功能
最傻的做法是没有时间更新权重,一通的爬,回头再一通的爬。
通常在下一次爬的的数据要跟上一次进行比较,如果连续5次都没有变化,那么将爬这个网页的时间间隔扩大1倍。
如果一个网页在连续5次爬取的时候都有更新,那么将设置的爬取时间缩短为原来的1/2。
5】 网络爬虫的效率相当的高
这是最关键的,涉及到MONEY, 别人一台机器一天能爬100G, 你要100台机器,那你死定了。
应该说各种爬虫的目的不一样,有的是爬邮件地址,有的爬客户信息,有的爬图片,有的爬音乐,有的什么都要(例如搜索引擎),但各种爬虫中,最重要的一点是下载效率要高,要能耗尽机器的资源。
机器的资源是什么呢? 最主要两种:CPU运算资源,网络带宽资源。在目前条件下,网络带宽资源更珍贵,所以优先耗尽带宽资源,如果带宽资源耗不尽时CPU都已经100%了,简单,再买一台机器。带宽比机器贵多了阿。
所以在爬虫程序中,效率是最关键的,下面是用糖果下载组件来实现的一个简单的爬虫,它能把任何机器的带宽耗尽,只要调节并发任务参数。当然百度地链接都是可下载的,即使所有url中有30%的死链接,依然可以达到这个速度,因为其并发参数是可调的, 发现下载速度小于最大速度时,增加并发任务数就可以了。
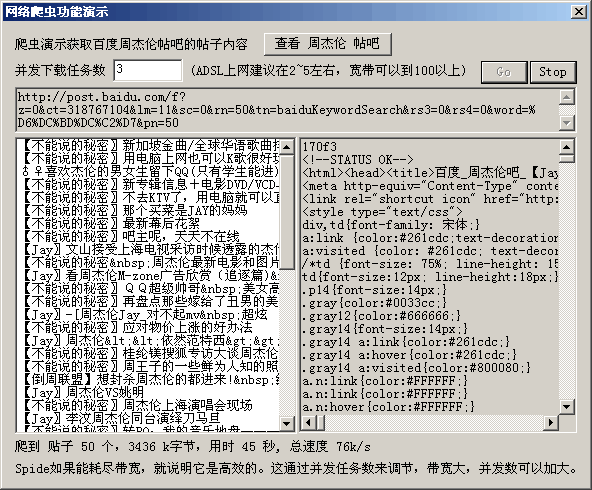
(本程序的VC6工程在糖果下载组件中安装包中提供)
测试时用的一台512K的ADSL上网机器,512K说的是位(bit), 转换为字节速度是512/8 = 64k字节/秒。 而这个爬虫的平均下载速度达到76k/s, 说明已经把带宽耗尽了。按照这个速度,这台机器一天能爬 76*86400 = 6.6G.
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=1789396